전체적인 그림은 아래 URL에서 추출
(https://www.slideshare.net/EdurekaIN/hadoop-mapreduce-framework)
(https://www.edureka.co/big-data-and-hadoop)
(http://www.admin-magazine.com/HPC/Articles/MapReduce-and-Hadoop)
(http://blog.raremile.com/hadoop-demystified/)
계속해서 하둡 맵리듀스에 관해 소개를 하고자 한다.
누군가에게 소개하는 것보다는, 개인적으로 공부하는 목적이 강하다. (= 두서 없음)
아파치 하둡 소개는 http://kkn1220.tistory.com/120 를 참고
Cloudera를 통한 HDFS 사용법은 http://kkn1220.tistory.com/121 참고
맵리듀스는 하둡에서 가장 중요하다고 해도 과언이 아니다.

맵리듀스는 하둡 클러스터의 데이터를 처리하기 위한 시스템으로, 여러 데이터 노드에 Task를 분배하는 방법이다.
맵, 리듀스로 구성이 되어 있으며 사실 이 사이에는 shuffle과 sort 단계가 들어 있다.
처리 과정
1) 맵리듀스는 Name Node의 Job Tracker 데몬에 의해 제어 된다.
2) 클라이언트는 맵리듀스 Job을 Job Tracker에게 보낸다.
3) 이 Job Tracker는 클러스터의 다른 Slave Node들에게 맵과 리듀스 Task를 할당하게 된다.
4) Slave Node는 Task Tracker 데몬에 의해 실행이 된다.
5) Task Tracker는 실제로 맵리듀스 Task를 실행하고, 진행 상황을 Job Tracker에게 전달하는 구조로 되어 있다.
그렇다면, 맵 리듀스는 왜 필요한 것일까???

전통적인(?, 사실 분산 프레임 워크가 나온지 오래 됐지만...더 이전) 데이터 처리 방법은 위와 같다. 매우 큰 데이터를 쪼개서 매칭되는 데이터를 뽑아, 결과를 추출하는 형식으로 되어 있었다.
실제로 빅데이터를 처리하기 위해 위의 구조로는 시간이 너무너무 오래 걸린다.


아래는 맵리듀스 프레임워크를 통해 결과를 추출하는 방식인데, 기존에 비해 두 가지 큰 이점을 가지고 있다.
1) Taking Processing to the data
2) Processing data in parallel
즉, 데이터를 처리하는데 있어 병렬적으로 할 수 있다는 것이다.
사실 위의 예제에서 Very Big Data가 작아보이긴 하지만, 실제 파일은 TB이상의 어마어마 할 것이다.
워낙 방대한 양이기 때문에 처리 프로세스는 간단해야 한다. 이를 위해, 기준이 되는 값이 필요한데 그 기준이 되는 값이 Key가 하나인 맵 구조이다.
내용이 좀 어려웠다. 아래의 사진을 보자.
맵리듀스 프레임워크
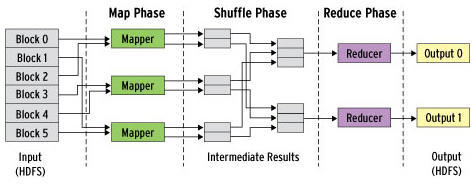
- Map Phase: 모든 입력 값에 대해 Map Function 을 적용하는 단계이다. 동시에 실행되는 여러 맵퍼는 각각 입력 데이터의 일부를 처리하는 단계를 포함하게 되는데, 이 여러 맵퍼 간에는 종속성이 없으므로, 서로 독립적으로 작업된다.
여기에서 알아둬야 할 것은, 맵퍼는 Key/Value 쌍의 형태로 데이터를 읽게 된다.
map(key, value) -> List(key, value)
ex) 소문자 바꾸기
input)
map(key, value) -> emit(k.toLower(), v.toLower())
result)
('TEST', 'LOWER') -> ('test', 'lower')
단, 출력 key값이 꼭 입력 데이터 key값과 동일할 필요는 없음(저 toLower()가 아닌, length()로 넣었을 때는 4가 됨)
- Shuffle Phase: 맵 단계로 부터 (key,value) pairs 결과 값에 대한 정렬 단계
(결과 값들의 키 순서대로 정렬되어 리듀서로 보내게 되는데 이를 sort라 함)
- Reduce Phase: 모든 Pairs를 통일한 키로 조합하여 정렬 된 목록을 생성함.
이 때, key와 value들의 리스트 값이 input값으로 들어옴. Reducer의 Output은 0이거나 Key/Value의 Pairs 값임
이 결과들은 다시 HDFS에 저장됨. (실제로 Reducer는 보통 Input값에 대해 하나의 Key/Value Pairs로 배출되어 사용)
reduce(key, list(values)) -> List(key, value)
예제
이 일련의 과정을 아래의 예제를 통해 설명하고자 한다.
역시, 예제를 통해 보는게 가장 쉽다고 생각~~!
맵리듀스 예제는 Word Count가 가장 많이 사용 된다.

1) Input값 입력: Input값으로 Dear Bear River 1줄, Car Car River 1줄, Deer Car Bear 1줄이 들어 왔다. 물론 이것은 어마어마하게 많은 데이터 일 것이다.
2) Split: split을 통해 단어를 쪼개는 작업을 수행하였다.
3) Map: 각 key(Deer, Bear, River)와 Value로는 Word Count이기 때문에 1로 지정이 된 것을 확인할 수 있다.
method Map(source, target)
emit(target, 1)
end
4) Shuffling: 각 Key와 Value의 List값이 Sort에 의해 정렬되어 있음을 확인할 수 있다. (B > C > D > R)
5) Reduce: 셔플링을 통해 들어온 Value of List 값을 더하는 작업을 수행하였다. (Word Count)
method Reduce(target, counts[c1,c2...])
sum <- 0
for all c in counts[c1,c2,...] do
sum <- sum + c
end
emit(target, sum)
end
6) Result: Final Result
위의 예제를 통하면 전체적으로 맵리듀스의 흐름을 파악할 수 있을 것이라고 사료된다.
'기타 > 분산 컴퓨팅' 카테고리의 다른 글
| Spark RDD 개념 및 예제 (0) | 2017.04.07 |
|---|---|
| Apache Spark 설치 (0) | 2017.04.07 |
| Apache Spark란 무엇인가? (0) | 2017.04.07 |
| 아파치 하둡 HDFS 사용법(Cloudera 사용) (0) | 2017.03.31 |
| 아파치 하둡 소개 (0) | 2017.03.31 |