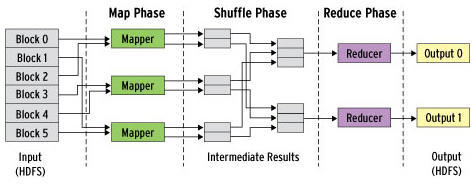
그림 발췌
Cluster에서 운영
- 분산 모드에서 스파크는 하나의 Driver Program과 여러 Worker Node 즉, Master/Slave 구조를 가진다.
Driver는 Worker Node의 Executor와 통신하는데, Driver는 자신만의 자바 프로세스에서 돌아가며, Executor 또한 독립된 자바 프로세스다.
- 하나의 Spark Application은 Cluster Manager라고 불리는 외부 서비스를 사용하여 여러 개의 머신에서 실행 된다.

- Driver: Driver는 Main Method가 실행되는 프로세스로, SparkContext를 생성하고 RDD를 만들고, Transformation과 Action을 실행하는 사용자 코드를 실행하는 프로세스
1) 사용자 프로그램을 Task로 변환
2) Executor에서 Task들의 Scheduling
- Executor: Spark Task를 실행하는 작업 프로세스. Spark application 실행 시 최초 한 번 실행되며, 대개 application이 끝날 때까지 계속 동작하지만, 오류로 죽더라도 Spark application은 계속 실행함
1) Application을 구성하는 작업들을 실행하여, 드라이버에 결과를 리턴
2) 각 Executor 안에 존재하는 블록 매니저라는 서비스를 통해 사용자 프로그램에서 Cache하는 RDD를 저장하기 위한 메모리 저장소 제공
- Cluster Manager: Spark와 붙이거나 뗄 수 있는 컴포넌트. (Yarn, mesos, 내장 Manager 등 다양한 외부 매니저들 위에서 동라가게 함)
Program 실행하기
- 어떤 Cluster Manager를 사용하든 Spark는 사용자 프로그램을 Spark에 submit 할 수 있는 단일 스크립트인 Spark-submit을 제공

$ ./bin/spark-submit <script.py> //local로 Spark program 실행
$ ./bin/spark-submit --master spark://host :7077 --executor-memory 10g <script.py>
--master flag는 접속할 cluster의 주소를 지정해주는데, spark:// URL은 Spark의 단독 모드를 사용한 cluster 의미

- Spark-submit –master flag값
1) spark://host:port: spark 단독 클러스터의 지정 포트 접속 (default: 7077)
2) memos://host:port: mesos cluster에 지정 포트 접속 (default: 5050)
3) yarn: yarn cluster 접속 (hadoop directory -> HADOOP_CONF_DIR 환경 변수 설정 필요)
4) local: 로컬 모드에서 싱글 코어로 실행
5) local[N]: N개코어로 로컬모드에서 실행
6) local[*]: 로컬모드에서 머신이 가지고 있는 만큼의 코어로 실행
- executor-memory <MEM>: executor 당 메모리 할당
- 자세한 내용은 spark-submit --help 참고

'기타 > 분산 컴퓨팅' 카테고리의 다른 글
| Spark Accumulator (0) | 2017.04.07 |
|---|---|
| Spark Data 불러오기/저장하기 (0) | 2017.04.07 |
| SparkContext, Reduce/Group By Key (0) | 2017.04.07 |
| Spark Pair RDD 개념 (0) | 2017.04.07 |
| Spark RDD 개념 및 예제 (0) | 2017.04.07 |