- 프로세스는 메모리에 상주핳여 실행중인 응용 프로그램이다. 응용 프로그램이란 프로세스가 인식 가능한 기계어로 구성되어 디스크에 저장되어 있는 코드의 집합이다. 응용 프로그램이 사용자 또는 커널에 의해 수행이 요청되었을 때 메모리에 적재되고 실행 가능한 상태로 전환되며 이를 프로세스라 한다. 프로세스는 태스크나 작업이라 불리기도 하며 동일한 의미를 가진다.
- 프로세스 상태
- 일반적으로 프로세스의 상태는 총 5단계로 프로세의 생성과 준비, 실행, 대기, 종료로 나뉜다.
1) 프로세스의 생성 단계(New)
- 프로세스의 생성 단계는 프로세스 수행을 위해 메모리 공간을 할당하고 응용 프로그램 코드를 메모리에 적재하는 단계이다.
2) 프로세스 준비 단계(Ready)
- 프로세스 준비 상태는 프로세스가 대기 큐에 삽입되어 스케줄러에 의해 CPU를 할당받아 수행되기를 기다리는 상태이다.
3) 프로세스 실행 단계(Running)
- 프로세스 실행 단계는 스케줄러로부터 CPU를 할당받아 수행하는 상태이다. 단일 CPU 시스템에서 실행상태에 있는 프로세스는 단 하나만 가능하다.
4) 프로세스 대기 상태(Waiting)
- 프로세스 대기 상태는 다른 프로세스로부터의 결과가 필요하거나 어떤 특정 시그널이 발생이 필요한 것과 같이 프로세스에 특정 이벤트가 발생하기를 기다리고 있는 상태이다.
- 리눅스에서의 프로세스 상태
- 리눅스 프로세스 상태는 프로세스 디스크립터의 state필드의 값으로 표현된다.
state 필드 값이 -1이면 실행할 수 없는 상태를 나타내고 0은 프로세스가 실행중인 상태, 0보다 큰 값은 멈춤상태를 나타낸다.
1) TASK_RUNNING
프로세스가 실행중이거나 실행 준비중인 상태
2) TASK_INTERRUPTIBLE
하드웨어 인터럽트가 발생하거나 프로세스가 필요한 자원을 사용할 수 있을때까지 대기하는 상태
3) TASK_UNINTERRUPTIBLE
외부에서 인터럽트를 받아도 프로세스 상태가 바뀌지 않음. 프로세스가 대기중에 외부의 이벤트로부터 방해 받지 않아야 하는 경우의 상태
4) TASK_STOPPED
외부로부터 SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU 와 같은 프로세스 작업을 중단시키는 시그널을 받아서 프로세스의 실행이 중단된 상태
5) TASK_TRACED
리눅스 커널 2.6버전에 추가된 프로세스 상태로 ptrace() 시스템 호출을 사용하여 다른 프로그램을 감시할 때 기존에는 프로세스를 TASK_STOPPED 상태로 변경하였으나 커널 2.6버전에서는 TASK_TRACED 상태로 변경
6) TASK_ZOMBIE
프로세스 실행이 종료되었지만 해당 프로세스의 부모 프로세스가 wait()나 waitpid() 와 같이 종료된 자식 프로세스 정보를 가지지 않는 경우 발생(자식프로세스가 종료 된 후 부모 프로세스는 자식 프로세스의 종료 상태값을 wait()나 waitpid()를 통해 요청할 있는데 이 때 자식 프로세스에 대한 프로세스 정보들을 메모리 상에 유지하고 있는 상태)
7) TASK_DEAD
프로세스 종료 상태
- 프로세스 상태코드(STAT)
- D(disk wait) : 디스크 입출력 대기같은 인터럽트 할 수 없는 대기 상태
- R(running or runable) : 프로세스가 실행중이거나 실행큐에 들어있는 실행 가능 상태
- S(sleep) : 인터럽트 가능한 대기 상태
- T(stopped) : 프로세스가 ^Z나 트레이스 명령 등으로 멈춘 상태
- W(paging) : 가상 메모리 사용 중.(2.6버전 커널부터 사용하지 않음)
- X(dead) : 실행 종료. 이후 나타나지 않음
- Z(zombie) : 좀비 프로세스
- 제어
1. bg/ fg
- 다중 작업을 위한 프로세스 명령어
- 프로그램을 실행 시킬 때, 일반적으로 그냥 실행시키면 포그라운드로 실행되고 명령어 끝에 &를 붙이면 백그라운드에서 실행
- 포그라운드는 사용자가 한 번에 하나의 명령만 수행 시킬 수 있었으나, 백그라운드는 한번에 여러 개의 명령 수행 가능
# sleep 1000 &
2. nohup
- SIGHUP(1, 연결 끊기), SIGTERM(15, 소프트웨어 종료)로 부터 보호하고, 터미널 없이 프로세스가 지속적으로 실행되게 만듦
- 종료나 중지를 무시하고 명령어를 현재 실행중인 프로그램이 있는 사용자가 로그아웃을 실행하게 되면 실행중인 프로그램도 같이 종료되는데 이런 경우 사용자가 로그아웃을 하더라도 실행중인 프로그램이 정상적으로 작업을 종료할 수 있도록 하는 명령어 실행 방법이 nohup
#nohup sleep 1000 &
로그아웃
로그인
#ps -ef | grep sleep
로그아웃 했어도 실행되는 것 확인 가능
3. jobs
- 백그라운드로 수행중인 모든 프로세스의 상태 출력
#sleep 10 &
#jobs
[1]+ Running sleep 10 &
4. kill/ killall, pkill
- 프로세스에 특정 시그널을 보낼 때 사용
#kill [-옵션] pid
#killall [-옵션] 명령어
#pkill [-옵션] 프로세스 이름
- 옵션
-s: 전송할 시그널의 이름이나 번호 지정
-p: 전송할 시그널을 출력만 함
-l: 시그널 목록 출력
[signal 종류]
1. HUP 연결끊기
2. INT 인터럽트
3. QUIT 종료
4. ILL 잘못된 잘못된 명령
5. TRAP 트랩추적
6. IOT IOT명령
7. BUS 버스에러
8. FPE 고정소수점예외
9. KILL 프로세스 죽이기(강제)
10. USR 1 사용자정의 시그널
11. SEGV 내용이 없는 파이프에 대한 시그널
12. PIPE 내용이 내용이 없는 파이프에 대한 시그널
13. USR 2 세그멘테이션 위반
14. ALRM 경고 출력 (알람 )
15. TERM 정상종료
16. KFLT 코프로세서스택실패
17. CHLD 자식프로세스 변화
18. CONT STOP 이후 계속 진행
19. TOP 정지
20. TSTP CTRL TZ
#kill 2344 (=kill -TERM)
#kill -9 2344
#kill -HUP 2344 (xinetd, sshd 등 수정된 config를 재 적용 시 주로 사용)
#killall -9 sshd
#pkill sshd (프로세스 이름으로 kill)
5. at, atq, atrm
- 특정 시간에 특정 작업 수행
- 지정한 작업은 queue(큐)에 저장되며 저장된 작업들은 /var/spool/at 디렉토리 아래 파일로 저장
- 옵션
-q queue : 작업의 대기큐를 지정한다. 사용할수 있는 큐는 a-z, A-Z
-c job : 작업리스트를 출력
-d : 작업을 삭제(=atrm)
-l : 큐에 있는 작업들을 보여준다. root 인경우에는 모든 작업들의 목록을 보여줌(=atq)
-m : 실행한 결과를 메일로 통보
- 시간 지정
- 시간지정은 HHMM, HH:MM형태로 가능하고 am,pm 으로 구분 가능
am,pm 등의 표기가 없을 경우에는 24시 표현으로 함
날짜의 경우 MMDDYY, MM/DD/YY, MM.DD.YY 형태
now (현재시간), tomorrow(내일), today(오늘), teatime(16:00),noon(12:00),
midnight(00:00)과 같은 문자열도 가능
- 관련 명령어
- atq
큐에 저장된 작업들을 보여주는 명령으로 at -l 실행결과와 같음
작업번호와 작업예정시간, 작업이 저장되어 있는 큐 보여줌
- atrm
예약된 작업을 취소할 때 사용하는 명령으로 큐에서 해당 작업 삭제
at -d와 같음
6. sleep
- 주어진 시간 만큼 지연
#sleep 3 //3초간 sleep
- 모니터링
1. top
- CPU 프로세스들을 출력, 매초별로 시스템 상태와 대부분의 프로세스들을 refresh 해서 실시간으로 화면에 보여줌
Line1: 시스템의 현재 시간과, uptime, 사용자수, 평균부하
Line2: 프로세스 상태
Line3: 사용자와 시스템, nice, 휴먼중인 프로세스 cpu 사용시간
Line4: 메모리상태
Line5: 가상메모리, 스왑상태
[#top]
10:27 am up 5 days, 22:52, 2 users, load average: 0.00, 0.00, 0.00
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND
537 root 13 0 1048 1048 824 R 1.1 0.8 0:00 top
1 root 0 0 423 428 380 S 0.0 0.3 0:06 init
...............................
- top 명령을 실행했을 때의 각 항목에 대한 설명
PID: Process ID
USER: 소유자
PRI Priority (우선순위)
NI Nice Value: -20~19사이의 값으로 작을수록 우선순위가 높아진다
SIZE: 프로세스의 코드와 데이터의 크기 (KB 단위)
SHARE: 프로세스가 사용하는 공유 메모리의 양
STAT S:Sleeping D:uninterruptible R: Running Z: Zombie T: sTop or Trace
%CPU: CPU 사용시간 퍼센트
%MEM: 메모리 사용 퍼센트
TIME: 프로세스가 시작하여 사용한 총 CPU시간
COMMAND: 프로세스를 실행한 명령어 라인
- top을 실행 중, 명령 설명
space: 화면 갱신
h: 도움말
u: 사용자별
k: 프로세스 죽이기
M: 메모리 사용율로 sorting
2. ps
- 시스템에서 현재 실행중인(sleep상태 포함) 프로세스에 대한 정보를 각 PID와 각 프로세스의 부모 ID(PPID)를 표시해 줌
[옵션]
-a 프로세스 현황 표시(다른유저)
-u 유저지향적(top 포맷)
-x 터미널 제어 없이 프로세스 현황 보기
-e 현재 시스템 내에서 실행중인 모든 프로세스 정보 출력
-f full listing(uid, pid, ppid, c stime, tty, time, cmd)
-o 유저 formatting
[출력 필드]
USER: 프로세스 소유자의 계정
PID: 프로세스 식별자
RSS: 프로세스에 의해 사용되는 실제 메모리 사용량(Kbyte)
SZ: 프로세스 자료와 스택의 크기(Kbyte)
TIME: 현재까지 사용된 CPU 시간(분,초)
TTY: 프로세스의 제어 터미널
%CPU: 전체 프로세스를 대상으로 CPU가 해당 프로세스를 실행한 CPU시간의 백분율
%MEM: 프로세스가 사용한 실제 메모리의 백분율
START: 프로세스 시작 시간
COMMAND: 명령어 이름
- 시스템 실행중인 전체 프로세스 확인
$ps -ef
- 시스템에서 실행중인 각 프로세스의 자원(CPU, Memory) 사용량과 상태 확인
$ps -aux
3. pstree
- 프로세스들을 계층적(트리구조)으로 출력해주는 명령어
- 모든 프로세스들은 명령 이름에 의해 리스트되고, 자식 프로세스는 부모 프로세스의 오른쪽에 나타남. 그러므로 최초로 실행되는 프로세스인 init(모든 프로세스의 궁극적인 부모)은 가장 왼쪽 상단에 출력
[옵션]
-a 각 프로세스의 명령행 인자까지 출력
-p PID 출력
#pstree -a
# pstree -a
init
|-acpid
|-atd
|-auditd
| |-audispd
............
4. nice
- 프로세스의 우선순위 조정(최고 -20, 최저 19)
#nice -n 5 make
5. strace
-시스템콜, 시그널 추적
6. ltrace
-라이브러리 콜 추적
- 리눅스 서비스 데몬
1. init 데몬
- 시스템 부팅시 커널이 로딩이 된후 커널에 의해서 실행이 되는 프로세스로 프로세스 id 는 1이다. 파일시스템의 구조를 검사하고 파일시스템을 마운트, 서비스 데몬을 띄우고 사용자 로그인을 기다리고 사용자를 위한 쉘을 띄우는 역할을 한다.
[/etc/inittab 파일의 내용]
id:5:initdefault:
si::sysinit:/etc/rc.d/rc.sysinit
l0:0:wait:/etc/rc.d/rc 0
l1:1:wait:/etc/rc.d/rc 1
l2:2:wait:/etc/rc.d/rc 2
l3:3:wait:/etc/rc.d/rc 3
l4:4:wait:/etc/rc.d/rc 4
l5:5:wait:/etc/rc.d/rc 5
l6:6:wait:/etc/rc.d/rc 6
ca::ctrlaltdel:/sbin/shutdown -t3 -r now
pf::powerfail:/sbin/shutdown -f -h +2 Power Failure; System Shutting Down pr:12345:powerokwait:/sbin/shutdown -c Power Restored; Shutdown Cancelled 1:2345:respawn:/sbin/mingetty tty1
2:2345:respawn:/sbin/mingetty tty2
3:2345:respawn:/sbin/mingetty tty3
4:2345:respawn:/sbin/mingetty tty4
5:2345:respawn:/sbin/mingetty tty5
6:2345:respawn:/sbin/mingetty tty6
x:5:once:/etc/X11/prefdm -nodaemon
[/etc/inittab 파일 설명]
/etc/inittab 파일의 각 행의 형식과 의미
name : level-number : options : process
name : 각항목의 이름들
level-number : 해당행의 설정내용을 어떤 부팅레벨에서 실행할 것인가를 설정
options: 다음에 오는 프로세스를 실행할 때 적용할 프로세스 속성
- respawn: 프로세스가 종료가 되면 다시 실행시켜주는 역할. 예를 들어, 가상콘솔에서 로그인해서 사용했다가 exit로 종료했을 때 다시 로그인창이 뜨는 경우가 respawn 속성
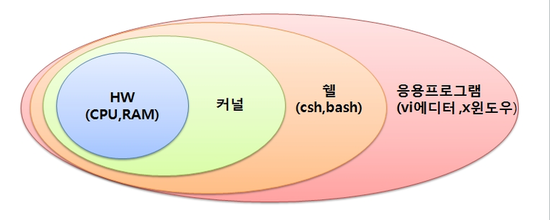
- 컴퓨터는 0과 1만을 이해할 수 있다. 하지만, 사람이 컴퓨터가 이해할 수 있는 0과 1만을 사용하여 명령을 내리기는 쉽지 않은 일이다. 그래서 쉘이라는 것이 명령어를 입력받아 이것을 컴퓨터가 이해할 수 있는 0과 1로 된 명령으로 바꾸어, 이 명령을 처리하는 커널에 전달하는 것이다.
- 쉘의 역할
사용자(User) <-> Shell(쉘) <-> kernel(커널) <-> 하드웨어
사용자가 로그인 할 때 자동적으로 쉘이라는 프로그램이 실행된다.
쉘에는 여러 종류가 있으나, 큰 갈래로는 Bourne Shell 과 C shell이 있다. 나머지들은 이들로부터 파생된 것들이다.
이중 리눅스에서 기본적으로 사용하고 있는 쉘은 bash 쉘로 Bourne Again Shell이란 뜻이다. 이것 역시 Bourne Shell로부터 파생된 것이다. 사용자가 원한다면, 사용하고자 하는 쉘을 변경할 수도 있다.
쉘이 프롬프트에 사용하는 기호는 쉘마다 다른데, 기본적으로 본 쉘과 콘쉘은 "$"을, C쉘은 "%"을 사용한다.
/etc/shells 파일을 열어 보면 사용할 수 있는 쉘들의 경로가 설정되어 있다.
/etc/passwd 파일을 살펴보면, 다음과 같이 사용자가 등록되어 있다.
test1:x:502:502:Test User:/home/test1:/bin/bash
마지막 항목(/bin/bash)이 사용자가 사용하는 쉘이다. 명령어을 처리하는 쉘을 얻지 못하므로 어떤 명령도 수행할 수가 없다
- 사용자 쉘 바꾸기
$echo $SHELL
/bin/bash
잠시 바꾸고 싶을 때는 사용하려는 쉘을 프롬프트에서 실행 시킨다. 그 쉘을 빠져나겨려면, 'exit' 명령을 사용한다. 기본 쉘을 변경하고 싶을 때는 chsh 명령을 사용하거나, /etc/passwd 파일의 쉘 부분을 변경 한다.
- 쉘 환경 설정
- 설정 파일
리눅스에서는 여러 가지 환경 설정 파일을 제공한다. 이것은 리눅스의 사용자를 더욱 자유롭고 융통성 있게 만들어 준다. 이런 파일들은 보통 홈디렉토리 안에 위치하고 있으며, '.'으로 시작 하는 파일들이다. 'ls -a' 명령으로 파일의 존재를 확인할 수 있다. 파일의 이름은 "Resource Configuration"이라는 의미의 "rc"라는 스펠링으로 끝나는 경우가 많다.
이런 파일들은 새로운 사용자를 등록하면, "/etc/skel " 디렉토리에 기본 값으로 저장되어 있는 파일들을 홈디렉토리에 복사하여 생겨나는 것이다.
물론, 그 중에는 쉘 구동 환경을 설정하는 파일들도 있다.
- 환경 설정 파일 설명
- .bashrc
쉘을 위한 쉘 스크립트로 스크립트로 서브 쉘, 즉 비로그인 쉘이 실행될 때 명령과 명령과 프로그램 구조로 구성할 구성할 수 있다 . 새로운 쉘이 실행될 실행될 때마다 때마다 실행
- .bash_profile
로그인 할 때 읽어 들이는 설정 파일 . 주요 설정 내용은 내용은 일반적으로 일반적으로 , 검색 경로 , 터미널 터미널 종류 , 환경변수등을 환경변수등을 설정하고 설정하고 , 그 외 로그인 로그인 시점에 실행 시키고 시키고 싶은 명령 , 시스템에 시스템에 대한 정보를 정보를 보여주는 보여주는 명령등을 명령등을 명령등을 수행
- .bash_logout
로그인 쉘이 종료 되면서 되면서 읽어 들인다 .
- 환경 변수
- 환경 변수는 쉘 환경을 입맛에 맞게, 혹은 필요에 맞게 설정하는데 사용되는 값들을 가지고 있다. 물론, 이 변수값을 수정함으로써 사용자마다 원하는 환경을 설정할 수 있다.
- 주요 환경 변수들
1) HOME : 사용자의 홈디렉토리
2) PATH : 실행파일을 찾는 경로
3) LANG : 프로그램 사용시 기본 지원되는 언어
4) PWD : 사용자의 현재 작업하는 디렉토리
5) TERM : 로긴 터미널 타입
6) SHELL : 로그인해서 사용하는 쉘
7) USER : 사용자의 이름
8) DISPLAY : X 디스플레이 이름
9) VISUAL : visual 편집기의 이름
10) EDITOR : 기본 편집기의 이름
11) COLUMNS : 현재 터미널이나 윈도우 터미널의 컬럼수
12) PS1 : 명령프롬프트변수
13) PS2 : 2차 명령프롬프트이다. 명령행에서 를 사용하여 명령행을 연장했을 때 나타난다.
14) BASH : 사용하는 bash 쉘의 경로
15) BASH_VERSION : bash의 버전
16) HISTFILE : history 파일의 경로
17) HISTFILESIZE : history 파일의 크기
18) HISTSIZE : history에 저장되는 갯수
19) HISTCONTROL : 중복되어지는 명령에 대한 기록 유무를 지정하는 변수이다.
20) HOSTNAME : 호스트의 이름
21) LINES : 터미널의 라인 수
22) LOGNAME :로그인이름
23) LS_COLORS : ls 명령의 색상관련 옵션
24) MAIL : 메일을 보관하는 경로
25) MAILCHECK : 메일확인시간
26) OSTYPE : 운영체제 타입
27) SHLVL :쉘의 레벨
28) TERM :터미널종류
29) UID : 사용자의 UID
30) USERNAME : 사용자이름
- Bash의 쉘변수
(1) 쉘변수
1) 개요: 말 그대로 특정한 쉘 즉 bash에서만 적용되는 변수를 말한다.
2) 특징
- 지정하는 방법은 '변수명=값' 형태로 지정하면 된다. 예) $ COLOR=red
- 변수값을 출력할 때는 변수명 앞에 $을 붙여 echo명령을 사용하면 된다.
예) $ echo $COLOR red
(2) 환경변수
- 모든 쉘에 영향을 미치는 변수라는 것을 제외하고는 쉘변수와 지정방법이나 특징이 유사하다.
(3) bash에서 쉘변수를 환경변수화시키기
- export명령을 사용하면 된다.
(사용 예제)
# mkdir $HOME/backup
# ls -ld $HOME/backup
drwxrwxr-x 2 kkn kkn 4096 8월 28 05:31 /home/kkn/backup
# echo $PS1
[u@h W]$
=> 프롬프트 형식
d : '요일 달 날짜'형태로 나타내준다. (예 "Wed Jan 15")
h : 호스트이름을 보여준다. 보통 '.'를 사용한 이름인 경우 첫번째 '.'까지 보여준다.
H : 호스트이름을 보여준다.
l : 쉘의 터미널 장치의 이름을 보여준다.
s : 쉘의 이름을 보여준다.
t : 24시 형태의 현재 시간을 보여준다. (예 HH:MM:SS)
T : 12시 형태의 현재 시간을 보여준다. (예 HH:MM:SS)
@ : am/pm 12시 형태의 현재시간을 보여준다.
u : 현재 사용자의 이름을 보여준다.
w : 현재 작업디렉토리를 보여준다.
W : 현재작업디렉토리의 마지막 디렉토리만 보여준다.
! : 현재 명령의 히스토리 넘버를 보여준다.
- 환경 변수 관련 명령
(1) set : shell변수를 표시하고 값을 지정할 수 있다. C-shell에서는 변수와 값 지정시에 필수적으로 사용해야 하지만, Bash에서는 변수와 값지정시에 꼭 set 명령을 지정하지 않아도 된다.
1) 사용법
set [option] [argument]
2) option
-o : 현재 set옵션의 상태를 표시한다.
3) 사용예
- set => 옵션이나 인자가 주어지지 않으면 이미 지정된 shell변수와 함수이름,값이 표시된다.
- set -o => 현재 set옵션의 상태가 표시된다.
4) 응용예
$ a=1 // bash에서는 set 명령없이 "변수=값" 형태로 지정 하면 된다. 확인은 인자없이 set 이라고 입력한다.
$ echo $a
1
=> 변수로 선언되었으므로 $a하면 1이라는 값이 출력된다.
$ /bin/csh // 임시로 C-shell로 전환.
$
=> C-shell로 전환하면 프롬프트로 바뀜을 알 수 있다.
$ b=2
b=2: Command not found. => bash에서 변수지정하는 것처럼 하면 오류가 나타남을 알 수 있다.
$ set b=2 => C-shell 계열에서는 변수와 값지정시 set 명령을 사용해야 한다.
확인하려면 인자없이 set 이라고 입력한다.
$ echo $b 2 => 변수로 선언되었으므로 $b하면 2라는 값이 출력된다
(2) env : 환경변수에 대한 정보를 보여준다.
1) 환경변수란 : 로그인할 때나 새로운 쉘을 파생시킬 때 쉘의 환경을 정의하는 중요한 역할을 수행한다. env를 실행하면 환경 변수 설정값들을 확인할 수 있고 또한 각 환경변수를 나타낼 때 변수이름 앞에 $를 붙인다.
2) 사용예
# env
=> 현재 시스템의 환경변수를 보여준다.
3) 환경변수의 설정 : 값을 지정한후 export해야 한다. 현재 리눅스의 bash에서는 export를 해도 반영된다.
-> X윈도우 구성(X protocol, X lib, X toolkit), GNOME, KDE 정의, 윈도우 매니저
- 업데이트: 2015년 8월 27일
- http://egloos.zum.com/xuny/v/553740 참고
- X window: X 윈도우는그래픽환경을제공해주는윈도우시스템으로이는분산형개방시스템을개발하기위한목적으로수행된 Athena 프로젝트의일환으로 MIT에서 1984년에개발됨.그후DEC HP SUN 등의기업들이참여한컨소시움형태로발전하면서 1987년 X11 버전을발표. 1999년 X11의기본형태를유지한 6번째릴리즈인 X11R6이발표되어현재가장많이사용되고있음
- X window 특징
1. 네트워크 기반의 그래픽 환경
2. 프로그램 작성 시 가장 많은 종류의 컴퓨터에서 구동 될 수 있을 정도로 좋은 이식성
3. 아이콘, 색상 등 그래픽 환경에 필요한 자원들이 특정한 형태로 정의되어 있지 않음
4. 사용자가 원하는 모양의 인터페이스 만들 수 있음
5. 디스플레이 장치에 의존적이지 않음
- X window 구성
1. 서버 /클라이언트
- 기본적으로클라이언트는응용프로그램을 지칭. X window클라이언트는직접적으로사용자와통신할수없음.클라이언트는서버로부터키보드나마우스입력같은사용자의입력을얻을수있음
X 서버란애플리케이션사용자의컴퓨터에서작동하며그래픽디스플레이하드웨어를제어하여개체를화면에뿌린뒤답신을보내게 됨
- GRUB은 실행과 함께 /boot/grub/grub.conf파일을 읽어서 어떤 부팅메뉴(커널)로 부
팅을 할 것인가를 결정하게 됨
- GRUB은 커널(kernel)이미지를 불러들임. 그리고 시스템 제어권을 커널에게 넘김
4단계: 커널의 로딩
- 커널은 swapper프로세스(PID 0번)를 호출
- swapper는 커널이 사용할 각 장치드라이브들을 초기화하고 init프로세스(PID 1번)를 실행
- init프로세스가 실행되면서 /etc/inittab파일을 읽어들여서 그 내용들을 차례대로 실행
5단계: init프로세스의 실행
각 부팅 레벨로 실행될 경우 /etc/rc.d/rcx.d의 파일들이 순차대로 실행됨(최근 우분투의 경우 etc/rcx.d)
- 시스템 부팅 레벨
0- halt
1- 단일 유저 모드
2- 멀티유저, 단 네트워크를 지원하지 않음
3- 멀티유저모드(default)
4- 사용되지 않음
5- X window 모드
6- reboot //6으로 하면 부팅될 때 무한 리부팅이 되려나..
- 파일시스템
http://egaoneko.github.io/os/2015/05/24/linux-starter-guide-4.html 참고
- 파일시스템(file system)은 컴퓨터에서 파일이나 자료를 쉽게 발견 및 접근할 수 있도록 보관 또는 조직하는 체계를 지칭
- 확장 파일 시스템(extended file system)
1. ext: 리눅스 초기에 사용되던 파일 시스템, 호환성 없음
2. ext2: ext3이 개발되기 이전 많이 사용되었음. 하지만 fsck(file system checker)하는 데 있어 오랜 시간 소요
[EXT2 아이노드]
- inode는 파일시스템의 가장 기본되는 단위
- 각각을 구분할 수 있는 고유 번호를 가지고 파일의 테이터가 어느 블록에 어느 위치에 저장되어 있는지, 파일에 대한 접근 권한, 파일의 최종 수정시간 그리고 파일의 종류등의 정보를 inode 테이블에 저장
- 저장되는 정보는 모드, 소유자 정보, 크기, 타임 스템프, 테이터 블록
- EXT2 에서 inode는 단지 하나의 파일, 디렉토리, 심볼릭 링크, 블록 장치, 문자 장치 등만을 나타냄
- 소유자 정보: 파일과 디렉토리에 대한 소유자와 그룹에 대한 식별자를 나타냄. 소유자 정보를 사용하여 파일이나 디렉 토리에 대한 접근 권한을 관리 가능
- 크기(size): 파일의 크기 정보를 저장한다. 파일에 대한 크기 정보는 바이트 단위로 저장
- 타임 스템프 (timestamps): inode가 생성된 시간과 최종적으로 수정을 가한 시간에 대한 정보를 저장
- 데이터 블록(Data Blocks): inode가 지정하고 있는 데이터 블록에 대한 포인터를 저장. 데이터블록에는 총 15개의 포인터가 존재하는데 이 포인터들 중에서 선행의 12개 포인터는 해당 inode가 지정하고 잇는 데이터에 대한 실제 블록에 대한 포인터 정보를 가지고, 나머지 3개의 포인터는 높은 수준의 간접 연결에 대한 정보를 가지고 있음
- Ext2 파일시스템은 clean bit 라는 특수 플래그를 갖는데, 파일 시스템이 동기화되고 깨끗하게 탑재 취소된 경우에 이 clean bit가 설정되며, 리눅스 시스템이 부팅할 때 clean bit가 파일 시스템에 설정되어 있으면, 해당 파일시스템은 완전성이 점검되지 않음
[EXT2 슈퍼블록]
- 슈퍼블록(Super Block)은 해당 파일 시스템의 기본적인 크기나 형태에 대한 정보를 저장
- 파일 시스템 관리자는 이 슈퍼 블록의 정보를 이용하여 파일 시스템을 활용하고 유지가능
- 슈퍼 블록에 저장되는 정보의 항목
매직 넘버(Magic Number): 마운트하는 소프트웨어에게 EXT2파일 시스템의 슈퍼 블록임을 확인 하게 하는 값
개정 래벨(Revision Level)
개정 래벨은 메이저 레벨과 마이너 래벨로 구성되어 있음
개정 래벨의 역할은 마운트 프로그램이 어떤 특정한 버전에서만 지원되는 기능이 이 파일 시스템에서 지원되는지에 대한 확인을 위해 사용되고 또한, 개정 레벨은 기능 호환성 항목을 포함하여 마운트 프로그램이 해당 파일 시스템에서 안정적으로 사용할 수 있는 기능이 무엇인지를 판단할 수 있는 기준을 제공
마운트 횟수(Mount Count)와 최대 마운트 횟수(Maximum Mount Count)
파일 시스템 전체를 검사할 필요가 있는지를 확인할 수 있음. 마운트 횟수는 마운트가 실행될 때마다 1씩 그 값이 증가하여 만약 마운트 횟수가 최대 마운트 횟수에 도달하게 되면 시스템은 e2fsck를 실행하라는 메시지를 내보내게 됨
블록 그룹 번호(block Group Number): 슈퍼 블록 복제본을 가지고 있는 블록 그룹의 번호를 나타냄
블록 크기(Block size): 파일 시스템의 블록 크기를 바이트 단위로 표시
그룹 당 블록수(Blocks per Grop): 하나의 그룹에 속한 블록의 수를 나타내는데. 이 수는 블록의 크기와 마찬가지로 파일 시스템을 만들 때 결정
프리 블록(Free Block): 파일 시스템 내부적으로 존재하는 프리 블록의 수를 나타냄
3. ext3: ext2의 단점을 보완하기 위해 저널링(Journaling)을 지원하도록 확장된 파일 시스템.
[자세히]
- 기존의 EXT2는 캐시에 저장되어 있는 테이터들을 디스크로 저장하는 도중 만약 시스템이 다운되거나 여러 가지 문제가 발생할 경우 파일 시스템이 손상되는 단점을 가짐
- 이를 위해 EXT2는 fsck(File System Check)라는 파일 시스템 복구 기능을 제공하지만 이 복구 방법은 복구하는데 시간이 만이 소요되는 문제점을 가짐
- 파일 시스템의 크기가 크다면 복구하는데 오랜 시간이 걸릴 뿐만 아니라 복구하는 동안시스템을 사용하지 못하고, 또한 슈퍼 블록에 마운트 횟수를 저장하는 영역이 있어서 마운트 횟수가 일정횟수 이상이 될경우에도 자동으로 fsck를 실행하게 됨
-> EXT3파일 시스템은 이러한 단점을 보안하기 위해서 저널링(Journaling)이라는 기능을 추가 해서 소개된 파일 시스템
- 시스템의 무결성은 물론 뛰어난 복구 기능까지 가짐
[저널링 기술]
- 데이터를 디스크에 쓰기 전에 로그에 데이터를 남겨 시스템의 비정상적인 셧다운에도 로그를 사용해 fsck보다 빠르고 안정적인 복구기능을 제공하는 기술
- 기존 EXT2 파일 시스템의 경우에는 시스템이 동작을 멈추기 바로 직전에 파일 시스템에 어떤한 수정을 가하고 있었는지 전혀 알 수 없었기 때문에 복구하기 위해서는 fsck에 의해서 관리되는 슈퍼 블록, 비트맵, inode 등을 모두 검사해야 하므로 시간이 오래 걸림
-> 저널링 기술은 사용한 파일 시스템의 경우 파일을 실제로 수정하기 전에 우선 로그에 그 수정된 내용을 저장하기 때문에 복구하기 위해서 로그만 검사하면됨. 로그를 바탕으로 다시 실제 파일 시스템에 수정 내용을 적용하기 때문에. 속도와 복구 안정성이 더욱 뛰어남
-> 이러한 동작 수행을 리플레이(Replay)이라고 함. 만약 해당 로그에 저장된 내용이 불안정할 경우에는 복구 자체를 포기하기 때문에 파일 시스템이 불안정한 상태로 되지 않음. 파일 시스템에 수정을 가하기 전에 우선 로그에 저장하는 이러한 파일 시스템의 특성 때문에 Log-Ging 파일 시스템이라 부르기도 함
4. ext4: ext3 파일시스템을 확장한 파일시스템으로 Extent라는 기능을 제공하여, 파일에 디스크 할당 시 물리적으로 연속적인 블록을 할당할 수 있도록 하여, 파일 접근 속도 향상 및 단편화5를 줄이도록 설계된 파일시스템
- 파일시스템 구조
http://egaoneko.github.io/os/2015/05/24/linux-starter-guide-4.html 만큼 잘 쓸 자신이 없어서 해당 링크가 더 이해하는 데 도움이 될 듯...
- 리눅스 주요 파일시스템 디렉토리 설명
/: root 파일 시스템
/bin: 가장 필수적인 실행 명령 디렉토리
/boot: 커널, grub 등 부팅 관련 파일
/dev: 장치 파일 모음
/lib: C라이브러리 등 필수적인 공유 라이브러리 위치
/proc: 시스템의 프로세스 정보를 위한 가상 파일시스템 디렉토리
/root: root 사용자의 홈디렉토리
/sbin: 시스템 관리자용 실행 명령 디렉토리
/tmp: 임시 파일 생성용 디렉토리
/usr: 각종 응용프로그램이 설치되는 디렉토리
/var: 시스템 운용 중 생성되는 로그를 포함하는 임시 파일
/mnt: 임시 마운트용 디렉토리
/home: 사용자 홈 디렉토리
- 리눅스 파일 시스템은 크게 네 가지로 구분
부트 블록
(Boot Block)
슈퍼 블록
(Super Block)
아이노드 블록
(Inode Block)
데이터 블록
(Data Block)
1. 부트 블록: 운영체제를 부팅시키기 위한 코드 저장됨
2. 슈퍼 블록: 파일시스템과 관련된 정보 저장
3. 아이노드 블록: 파일에 대한 정보를 저장하고, 모든 파일은 반드시 아이노드 블록을 하나 가지고 있음
4. 데이터 블록: 파일이 보관해야 하는 데이터를 저장
있
*아이노드 블록에는 파일 유형, 접근권한, 하드링크 수, 소유주 이름, 그룹 이름, 파일 크기, 생성 날짜가 저장 되어 있고, 파일 이름은 디렉토리 파일의 데이터 블록에 저장됨!
- http://weroot.co.kr/solaris/643 (RAID 장점, 그림 삽입)
- http://smsinfo.tistory.com/176 (본문의 예)
- RAID(Redundant Array of Independent)
- 여러 대의 하드디스크가 있을 때 동일한 데이터를 다른 위치에 저장하는 방법. 입출력 작업이 균형을 이루게 되어 전체적인 성능 향상
- 여러 개의 디스크를 배열하여 속도의 증대, 안전성의 증대, 효율성, 가용성의 증대를 하는데 쓰이는 기술
- RAID 장점
1. 운용 가용성, 데이터 안정성 증대
- RAID 1(mirror) 또는 RAID5 의 경우 볼륨에 포함되어 있는 디스크 중 하나의 디스크에 장애가 발생하더라도 남은 디스크가 백업 역할이 가능
(이로 인해 데이터 손실로 인해 복구하는데 소요되는 시간 없이 운용 지속 가능)
2. 디스크 용량 증설 용이
- RAID 0(Concatenate)의 경우 기존의 사용하던 디스크를 제외한 여분의 디스크가 하나 있을 경우 기존 사용하던 디스크의 데이터를 보존한 상태로 여분의 디스크와 하나의 볼륨으로 구성하여 사용 가능
3. 디스크 I/O 성능 향상
- RAID 0(Stripe)의 경우 데이터를 구성된 디스크들에게 나눠 저장하므로 I/O 성능 향상의 효과 있음
- RAID 종류
1. RAID 0: RAID 0에는 두 가지 방식이 있음 (필요 드라이브 최소 2개 이상)
- Concatenate(concat) 방식
- 두 개 이상의 디스크에 데이터를 순차적으로 쓰는 방법
- 장점: 디스크 기본 공간이 부족할 때 데이터는 보존하며 여분의 디스크를 볼륨에 포함하여 용량 증설 가능
- 단점: RAID 0의 특성상 디스크 중 하나의 디스크라도 장애 발생시 복구 어려움. 오류검출 지원안함
- Stripe 방식
- 흔히 RAID 0 이라고 하면 Stripe 방식을 말하는 것으로 생각하면 됨
- 하나의 데이터는 Stripe 기술을 이용하여 여러개의 같은, 일정한 크기로 나뉘게 됨. 이 하나하나의 조각을 Stripe Unit이라함
- 장점: 데이터를 사용할 때 I/O를 디스크 수 만큼 분할하여 쓰기 때문에 I/O 속도가 향상 되고 I/O Controller나 I/O board 등 I/O를 담당하는 장치가 별도로 장착된 경우 더큰 속도 향상 볼 수 있음
- 단점: Stripe를 구성할 시 기존 데이터는 모두 삭제.RAID 0구성 시 중요데이터는 반드시 백업!
- 예) "리눅스마스터" 라는 단어를 2개의 드라이브로 구성된 RAID 0에 저장한다면
하나의 드라이브는 "ㄹㄴㄱㅅㅁㅅㅌ"라는 자음을 저장하고
나머지 드라이브는 "ㅣㅜㅡㅏㅡㅓ"라는 모음을 저장하게 된다.
그렇기 때문에 저장하거나 불러오는 속도는 빠르지만 에러 발생 시 완전한 데이터를 불러오지 못하게 됨. 즉 안정성이 낮은 구성
2. RAID 1 (mirror)
- 적어도 2개의 디스크가 사용되며, 하나의 하드디스크에 기록되는 모든 데이터가 나머지 하나의 하드디스크에 복사되는 방법으로 아예 똑같기 때문에 mirroring이라고 함 (필요 드라이브 최소 2개 이상)
- 장점: 볼륨 내 디스크 중 하나의 디스크만 정상이어도 데이터는 보존되어 운영이 가능하기 때문에 가용성이 높음, 안정성이 상당히 우수함
- 단점: 용량이 절반으로 줄고(2개의 경우) 쓰기 속도가 느려짐
3. RAID 2
- 디스크들간의 Stripe를 사용하며, 몇몇 디스크들은 에러를 감지하고 수정하는 ECC 정보를 가짐
- 기록용 드라이브와 데이터 복구용 드라이브를 별도로 두는데 4개 하드디스크에 기록하기 위해서는 3개의 부가 데이터를 기록해야 하기 되기 때문에 효율성 측면에서 거의 사용하지 않음
- RAID 0처럼 Stripe 방식이지만 RAID 0 은 에러체크를 하지 않는 반면 에러체크와 수정을 할 수 있도록 Hamming Code 사용하는 것이 특징
4. RAID 3,4 (필요 드라이브 최소 3개 이상)
- RAID 3, 4는 RAID 0, 1의 문제점을 보완하기 위한 방식
- 기본적으로 RAID 0과 같은 Stripe 방식 사용을 사용하여 성능 보완 및 추가로 에러 체크 및 수정을 위한 패리티 정보를 별도의 디스크에 따로 저장함
- 3은 Byte 단위로 데이터를 저장하는 반면, 4는 블록 단위로 저장한다는 차이점이 있음
-> 블록 단위로 저장할 경우 작은 파일의 경우 한번의 작업으로 데이터를 읽을 수 있기 때문 성능상의 장점이 있음. 또한 3은 동기화를 거쳐야 되기 때문에 3보다는 4를 많이 사용함
-> 데이터가 저장되어 있는 드라이브에 장애가 발생할 경우 패리티 정보를 이용하여 복구를 할 수 있으나, 정작 패리티 정보가 저장되어 있는 하드디스크에 장애가 발생하면 복구 불가능
-> 또한, 패리티 하드디스크에 병목현상이 생겨 속도가 저하될 수 있음
- RAID 0 의 구성에 백업용 드라이브를 하나 더 달아서 안정성을 확보한 구성
5. RAID 5 (필요 드라이브 최소 3개 이상)
- 레벨 3과 레벨 4의 단점을 보완한 방식으로, 패리티 정보의 저장을 전달하는 하드디스크 대신 모든 하드디스크에 패리티 정보를 분산 저장
-> 쓰기(Write)에는 패리티 정보가 분산되어 저장되기 때문에 Level 3,4의 단점인 병목은 줄여주지만 읽기(Read)에서는 사방에 흩어져 있는 패리티 정보를 갱신하며 일게 되기 때문에 성능 저하 있음
- RAID 3,4와 달리 패리티 정보가 저장된 디스크가 따로 없어 패리티 디스크 고장과 같은 문제에서 자유롭고 실제 서버/워크스테이션에서 가장 많이 사용하는 방식
- 여러개의 디스크를 Stripe 방식으로 볼륨을 구성하고, 패리티 정보를 사용하여 데이터의 정합성 제공
- 장점: 데이터의 정합성의 유지 및 RAID 1에 비해 용량 활용성 높음
- 단점: 데이터를 쓸 때마다 패리티 연산을 해야하고, 이로 인해 부하 발생
(쓰기 작업이 많은 서버의 경우 RAID 1구성이 나을 수 있음)
6. RAID 6 (필요 드라이브 최소 4개 이상)
- RAID 5와 같은 개념이지만 다른 드라이브 간에 분포되어 있는 2차 패리티 정보를 넣어 2개의 하드에 문제가 생겨도 데이터를 복구할 수 있음. 즉 RAID 5보다 데이터 안정성 고려
- 하드를 스트라이핑으로 묶었기 때문에 RAID 0+1이나 RAID 10(1+0)보다 성능은 더 높고 신뢰성도 우수 하지만 패리티 정보를 2중으로 저장하면서 읽기 성능은 RAID 5와 비슷하지만 쓰기 작업 구현이 아주 복잡해서 일반적으로 잘 사용하지 않음
7. RAID 7
- 하드웨어 컨트롤러에 내장되어 있는 운영체제를 사용하여 속도가 빠른 버스를 통한 캐시, 독자적인 컴퓨터의 특성을 포함.(잘 사용안함..)
8. RAID 0+1, RAID 1+0 (필요 드라이브 최소 4개 이상)
- RAID 0과 1의 복합 구성. 즉 0의 Stripe 방식과 1의 Mirror의 기능이 합쳐진 것으로, 분산 저장을 통한 성능 향상, 데이터의 안정성 또한 보장 할 수 있음
-> 그러나 여전히 전체 용량의 50%만 사용할 수 있으며, 비용이 많이 드는 문제점 발생
- 성능은 비슷하지만 가용성 측면에서는 RAID 1+0이 높아 많이 사용함
- RAID 1+0은 RAID 0+1과 비슷한 개념이지만 구성순서의 차이가 있음. mirror를 먼저 구성한 뒤 두개의 볼륨을 Stripe로 묶는 순서로 구성
- 예)
1. DISK 1,2(혹은 3,4)에 장애 발생의 경우 사용 가능 O 사용 불가 X 2. DISK 1,3(혹은 2,4)에 장애 발생의 경우 사용 불가 X 사용 가능 O 3. DISK 1,4(혹은 2,3)에 장애 발생의 경우 사용 불가 X 사용 가능 O
1 의 경우RAID 0+1은3,4에 1,2의 데이터를 그대로 보존하고 있기 때문에 사용 가능하지만RAID 1+0은 1,2에 데이터가 없기 때문에 사용이 불가능
2과 3의 경우RAID 0+1은 두개의 Stripe 볼륨에 멤버인 디스크가 하나 씩 장애가 발생하므로볼륨 전체가 깨져서 사용이 불가능하나 RAID 1+0의 경우에는 mirror 에 멤버인 디스크에 장애가 발생하였으므로데이터를 보존하고 있어 사용이 가능
-> 이로 인해RAID 0+1은 가용성이 33.3%이지만RAID 1+0은 66.6%로두배의 고가용성을 확보할 수 있는 장점이 있음
- 드라이브가 6개일 때
- RAID 0+1은 RAID 0으로 구성된 드라이브들을 최종적으로 RAID 1로 묶는 것이라 각각 3개씩 하드 가 나눠지며, RAID 1+0은 2개씩 RAID 1으로 묶여있는 하드들이 RAID 0으로 구성됨
RAID 0+1의 경우 1개의 하드만 고장나서 복구해도 다른 RAID 0 구성에서 나머지 하드까지 데이터 전체를 복구해야 하지만, RAID 1+0으로 만든 시스템은 고장난 하드가 하드 1개라고 하면 미러링으로 묶인 하드를 통해 데이터만 복구하면 되므로 실제로 운용하는데는 RAID 1+0 이 훨씬 유리
- 대부분의 사용자들은 PC라는 동일한 환경에서 프로그램을 작성 및 컴파일하고 동일한 환경에서 실행한다. 이 때 컴파일을 네이티브컴파일이라 하고
PC 환경에서 라즈베리용 모듈을 컴파일하여라즈베리 환경에서 실행. 즉 컴파일은 PC에서 하였고 실행은 라즈베리 파이 환경에서 하는데 이렇게 동작하는 환경과 시스템이 다를 때 이 컴파일을 크로스 컴파일이라고 함
1. 라즈베리 파이 커널 소스 다운로드
$ git clone --depth=1 https://github.com/raspberrypi/linux //depth의 경우 히스토리는 복제하지 않기 때문에 빠름
$ make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf-
bcm2709_defconfig
-2번째 줄의 경우 라즈베리파이2는 kernel7이다. 라즈베리파이2의 boot partition에는 kernel도 있고 kernel7도 있으니 혼동 주의
$ make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- zImage
modules dtbs
-Note: To speed up compilation on
multiprocessor systems, and get some improvement on single processor ones,use -j
n where n is number of processors * 1.5. Alternatively, feel free to
experiment and see what works
4. SD card에 직접 설치
-리눅스머신에서$lsblk을 입력할 경우(SD card input) sdb1,2가 나오는 것을 확인할 수 있다.(NOOBS의 경우 최소 5개)이 때, 1은 FAT partion, 2는 ext4 partion이다.
-mount
$ mkdir mnt/fat32
$ mkdir mnt/ext4
$ sudo mount /dev/sdb1 mnt/fat32
$ sudo mount /dev/sdb2 mnt/ext4
-모듈설치
$ sudo make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf-
INSTALL_MOD_PATH=mnt/ext4 modules_install
*arm-linux-gnueabihf는 앞 장의 컴파일러 path, INSTALL_MOD_PATH는 설치할 path 경로
- kernel image(mkknlimg스크립트로 변환 필요), dtb(device tree blob) 복사
- A standalone .img
file is a complete byte-for-byte image of an entire SD card. It includes the MBR (which stores
the partition table) as well as all the raw partitions.This is the lowest-level possible way
of writing an SD card, but it's the only way to access multiple partitions on an SD card using Windows (via the Win32DiskImager software).
-Raspbian이미지를 설치하면 2개의 파티션 boot(fat)와 file system(ext4)로 나뉘게 됨
-Boot(fat, sdb1) – boot partion으로 라즈베리파이펌웨어와컴파일드 된 리눅스커널과 몇 개의 config파일을 가짐
-File system(ext4,
sdb2)- root partition으로 application과 home directory등 리눅스에서 사용되는 파일들을 포함
-SD카드에 직접 이미지를 복사하게 때문에 큰 용량의 SD카드의 경우 지정된 용량의 공간을 할당하게 된다. 그렇기 때문에 앞서 설명했듯이, raspi-config에서 1. Expand_FileSystem으로최적화 시켜야 됨
§Standalone booting
-라즈베리파이는 bootstrap code를 사용하지 않음
1.Boot partition에 있는 bootcode.bin을 load
2.Run start.elf(and fixup.dat)
3.Config.txt 파일을 읽고 GPU configuration을 set up
4.Cmdline.txt(ext4 읽으라는 내용 포함 되어 있음)파일을 읽고 kernel.img 파일을 실행